День первый, обзорный¶
И сегодня нас ждут следующие темы:
Определения и примеры,
Элементы теории вероятностей и математической статистики,
Немного о том, почему машинное обучение вообще работает,
Об инструментарии:
jupyter labиpython,Как делаются исследования в сфере анализа данных, процесс,
Обзор дальнейших разделов курса на примерах результатов.
1.1 Определения алгоритма, модели, метрик и задач машинного обучения¶
Формальные определения требуют владения серьезным математическим аппаратом. Мы попробуем обойтись без этого.
Самое первое, из того что нам понадобится, это понятие датасета (или набора данных). Это прямоугольная таблица значений, каждая строка которой называется пример, или же sample, а каждая колонка - признак или, что то же самое, feature.
Индекс примера |
Признак_1 |
Признак_2 |
Признак_3 |
Признак_4 |
Признак_5 |
|---|---|---|---|---|---|
1 |
10 |
20 |
“строка 1” |
True |
3.1415926 |
2 |
15 |
10 |
“строка 2” |
False |
2.71 |
3 |
12 |
40 |
“строка 3” |
False |
-1.12345 |
Для задач обучения с учителем, один выбранный признак - вся колонка - объявляется как целевая величина, или target (часто обозначают как y), оставшиеся признаки мы так и будем называть признаками (features), их часто обозначают как X.
В задаче обучения с учителем, необходимо предсказывать целевую величину с помощью входных признаков. Она называется “с учителем”, потому что для ряда примеров у нас есть правильные ответы, и на них можно “научиться” предсказывать.
Для задач обучения без учителя - правильных ответов нет, и задача исследователя - найти некоторые полезные структуры в данных.
Что позволяет научиться машине предсказывать ответы или исследовать данные? Снова обойдемся без очень формальных определений, так как приведенные ниже определения сконструированы именно под этот курс.
Модель - это функция, которая принимает одно или более значений на входе, выдаёт значения на выходе (чаще всего одно - предсказание целевой величины),
Метрика - это число, получаемое в результате сравнения известных правильных ответов, и тех, которыми отвечает модель. Иногда это можно называть ошибкой модели,
Алгоритм - это инструкции, которые принимают на вход данные, а выдают на выходе модель.
В машинном обучении существует множество заготовленных алгоритмов, которые позволяют по данным строить модели так, чтобы ошибка модели была насколько это возможно меньше.

По типу значений целевого признака при обучении с учителем, задачи делят на как минимум следующие:
Регрессия - когда целевой признак, это любое вещественное число (с запятой), например рост, вес, количество денег,
Классификация - когда целевой признак принимает значения из заранее заданного множества (да/нет, собака/кошка/лошадь/…).
Пример¶
Давайте рассмотрим пример алгоритма, модели и метрики. В этом разделе уже пойдет код, вдаваться в детали которого мы пока не будем, но в этом же лекционном дне далее станет ясно, что в нём происходит.
Представим себе ситуацию, когда мы случайно попадаем на необитаемый остров, и видим незнакомый нам фрукт. С легкой руки назовём мангустин. Мы попробовали 10 таких фруктов, и составили таблицу.
Для каждого мангустина, мы некоторым образом знаем его размер в сантиметрах и вес в граммах, а также вкусный он или нет (да/нет).
%matplotlib inline
# магическая команда для отображения диаграмм в jupyter-тетрадках
# импорт библиотек
import numpy as np # библиотека для удобной работы с массивами
import pandas as pd # библиотека для удобной работы с датасетами
import matplotlib.pyplot as plt # библиотека для графики
import seaborn as sns # библиотека для отображения диаграмм
# создадим наш датасет и наполним его синтетическими данными
dataset = pd.DataFrame({
'weight': np.linspace(50, 125, 10), # 10 записей
'radius': np.linspace(0.5, 3.5, 10), # еще десять записей,
'tasty': [False] * 4 + [True, False] + [True] * 4 # наш целевой признак
})
dataset
| weight | radius | tasty | |
|---|---|---|---|
| 0 | 50.000000 | 0.500000 | False |
| 1 | 58.333333 | 0.833333 | False |
| 2 | 66.666667 | 1.166667 | False |
| 3 | 75.000000 | 1.500000 | False |
| 4 | 83.333333 | 1.833333 | True |
| 5 | 91.666667 | 2.166667 | False |
| 6 | 100.000000 | 2.500000 | True |
| 7 | 108.333333 | 2.833333 | True |
| 8 | 116.666667 | 3.166667 | True |
| 9 | 125.000000 | 3.500000 | True |
Все наши знания о мангустинах приведены в этой таблице. Нам надо использовать некоторый алгоритм, который создаст модель для предсказания по размеру и весу - будет ли мангустин вкусным. Сначала отобразим наши данные на плоскости, возможно это позволит сделать некоторые предположения.
sns.scatterplot(x="weight", y="radius", hue="tasty", data=dataset); # зададим что по осям и что брать за цвет
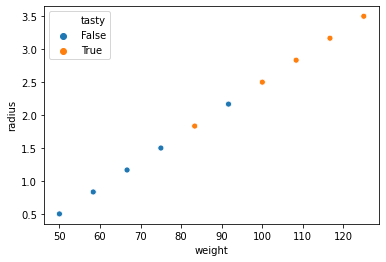
Уже из данной диаграммы видно, что чем больше размер и вес, тем мангустин обычно вкуснее, но есть и исключения. Мы не будем особо мудрствовать, и используем следующий метод для построения модели
Модель - пусть это функция \(tasty = f(weight, radius) > threshold = weight * a + radius * b > threshold\), где
a,b, иthreshold- называются параметрами модели,Метрика (ошибка модели) - количество неправильно классифицированных примеров,
Пусть N - количество примеров (известных нам мангустинов), и пусть наш алгоритм будет следующим:
$\(a = \frac {max(weight) - min(weight)} {N},\)\(
\)\(b = \frac {max(radius) - min(radius)} {N},\)$
threshold же находится перебором с шагом 1 по всем записям, лучшим считается тот, который дает минимум нашей метрике.
# наша арифметическая модель
def model(weight, radius, a, b, threshold):
return weight * a + radius * b > threshold
# подсчет метрики как суммы несовпадающих ответов
# True соответствует 1, False соответствует 0
def metric(y_true, y_predicted):
return sum(y_true != y_predicted)
def algorithm_create_model(data):
# здесь .max и .min - это всей колонке нашей таблицы
a = (data.weight.max() - data.weight.min()) / len(data)
b = (data.radius.max() - data.radius.min()) / len(data)
best_metric = np.inf # инициализируем бесконечностью
best_threshold = None
# перебор будем вести до максимума значений до сравнения
model_maximum = data.weight.max() * a + data.radius.max() * b
# для каждого порога
for threshold in np.arange(0, model_maximum, 1.):
y_predicted = []
for index in range(len(data)): # пройдем по всем примерам
predicted = model(
data.weight.values[index],
data.radius.values[index],
a, b, threshold
)
# подсчитаем прогноз модели
y_predicted.append(predicted)
# подсчитаем метрику по всем примерам
current_metric = metric(
y_true=data.tasty,
y_predicted=y_predicted
)
# сверим, дает ли текущий порог лучше качество
# и сохранием его, если так
if current_metric < best_metric:
best_metric = current_metric
best_threshold = threshold
print("Порог %.1f дал улучшение, неправильных ответов %d" % (
threshold, current_metric
))
return [a, b, best_threshold]
algorithm_create_model(dataset)
Порог 0.0 дал улучшение, неправильных ответов 5
Порог 376.0 дал улучшение, неправильных ответов 4
Порог 438.0 дал улучшение, неправильных ответов 3
Порог 501.0 дал улучшение, неправильных ответов 2
Порог 563.0 дал улучшение, неправильных ответов 1
[7.5, 0.3, 563.0]
ВАЖНО!¶
Мы “обучили” модель на всех доступных данных, и мы НЕ можем быть уверенными, что она их просто не запомнила. Чтобы быть до некоторой степени уверенным, мы должны проверять качество модели на отложенном тестовом множестве.
Перемешаем данные и проверим предсказания на трех отложенных мангустинах.
data = dataset.copy().sample(
frac=1., # выберем все записи в случайном порядке
random_state=1 # зафиксируем генератор случайных чисел для воспроизводимости
)
# отложим наши множества, в тестовом будет только три случая с конца
train = data[:-3]
test = data[-3:]
a, b, threshold = algorithm_create_model(train)
"Количество неправильных предсказаний из 3 тестовых: %d" % metric(
test.tasty,
model(test.weight, test.radius, a, b, threshold)
)
Порог 0.0 дал улучшение, неправильных ответов 4
Порог 536.0 дал улучшение, неправильных ответов 3
Порог 626.0 дал улучшение, неправильных ответов 2
Порог 715.0 дал улучшение, неправильных ответов 1
Порог 805.0 дал улучшение, неправильных ответов 0
'Количество неправильных предсказаний из 3 тестовых: 1'
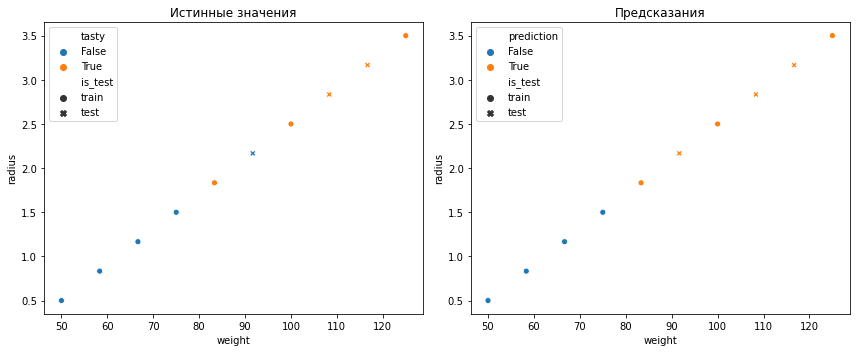
Как видим, наша модель ошибается в 1 случае из 3. Можно догадаться, что она ошибается в том случае, когда метки нарушают возрастающий порядок в размерах и весе мангустина.
# посмотрим как предсказывает наша модель все данные и отобразим наши множества разными маркерами
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1);
plt.title("Истинные значения");
sns.scatterplot(x="weight", y="radius", hue="tasty", style="is_test", data=pd.DataFrame({
"weight": data.weight,
"radius": data.radius,
"tasty": data.tasty,
"is_test": [
"test" if sample_index in test.index else "train" for sample_index in data.index
]
}));
plt.subplot(1, 2, 2);
plt.title("Предсказания");
sns.scatterplot(x="weight", y="radius", hue="prediction", style="is_test", data=pd.DataFrame({
"weight": data.weight,
"radius": data.radius,
"prediction": model(data.weight, data.radius, a, b, threshold),
"is_test": [
"test" if sample_index in test.index else "train" for sample_index in data.index
]
}));
plt.tight_layout();
Заключение¶
В данном курсе мы в основном не будем составлять собственные алгоритмы, а будем пользоваться уже готовыми. Их много, и работают они хорошо в разных случаях. За каждым из них стоит некоторая своя интуиция, как в случае алгоритма выше стояла следующая: чем выше размер и вес мангустина - тем он, начиная с некоторого порога, вкусный.
Другие данные могут давать (совсем) другие подсказки, и поэтому мы уделим внимание и разведочному анализу данных, цель которого - найти эти подсказки в данных и выбрать алгоритм получше.
Также из основного, следует понимать, что мы обязаны проверять качество на тех данных, которые модель не видела, что избежать самообмана. Модели, как и люди, могут запоминать правильные ответы (и далее мы даже увидим построенный на это алгоритм), и ничего не обобщать (no generalization). Отсутствие обобщения - это то, чего мы будем избегать, стараясь при этом минимизировать ошибку.
1.2 Элементы теории вероятностей и математической статистики¶
Начнем с того, что всё что случайно, как ни странно, случайно по-разному. Например, и монетка, и игральный кубик - с равной вероятностью выдают свои исходы. Но, например, попадание выпущенной из лука стрелой “в десяточку” - тяготеет все же к этой самой десяточке, хотя и случайным образом в неё иногда не попадает.
Как и в случае с алгоритмами и моделями, мы в рамках этого курса не будем вдаваться во все математические детали определений (хотя они очень важны). Ограничимся лишь тем, что нам потребуется.
Случайная величина - это величина, принимающая какой-либо исход из множества для неё возможных. Например, случайная величина на (0, 1) принимает значения только из этого интервала (непрерывная случайная величина, её исходы всегда между нулем и единицей). Или, случайная величина может принимать два исхода {-1; 1} - дискретная случайная величина.
Вероятность - это число от 0 до 1 (включительно), характеризующее, условно, как часто мы в конкретный исход попадём, или же насколько мы верим в то, что он произойдет (это так, если мы еще ни разу не проводили испытаний).
Например, для дискретной величины
{-1, 1}, если вероятность для-1равна0.3, мы будем считать что это означает, что в 100 испытаниях нам выпадет-1как раз 30 раз. Для непрерывной, вероятность определяется не в точке, а в луче: вероятность чтовеличина < 0.5равна0.3, означает что в точках менее 0.5 величина будет в 3 случаях из 10.
Формально, определения немного (если не сказать совершенно) другие. Но для наших нужд такого подхода будет достаточно.
Функция распределения случайной величины - описывает как раз все вероятности для всех исходов. То есть 0 < F(x) < 1, для любого x из множества исходов величины. Плотность распределения - это производная функции распределения (её определенный интеграл даёт вероятность).
Давайте на примерах.
Посмотрим на равномерно распределенную на (0, 1) случайную величину. Равномерно, это означает что чем длинее отрезок, тем пропорционально выше вероятность попасть в него.
X = [] # массив, где будут наши случайные величины
for index in range(1000): # цикл от 0 до 999
X.append(np.random.uniform())
# и отобразим количество попаданий точки это величины
sns.distplot(
X,
kde=False # не делать оценку плотности распределения
);
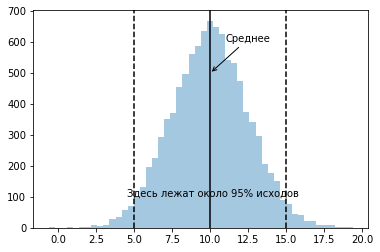
Рассмотрим распределенную на (-Infinity, +Infinity) случайную величину, со средним значением в числе 10, и такую чтобы её значения с чуть более чем 95%-вероятностью попадали в диапазон от +5 до +15.
Для того, чтобы значения нормально распределенной случайной величины (это значит функция распределения имеет определенный заданный вид, пока не суть какой) в более чем 95% случаев лежали в заданном диапазоне (среднее - L, среднее + L), нужно задать её стандартное отклонение как L / 2.
X = [] # массив, где будут наши случайные величины
for index in range(10000): # цикл от 0 до 9999
X.append(np.random.normal(
10, # среднее
2.5 # это половина ширины диапазона
))
# и отобразим количество попаданий точки это величины
sns.distplot(
X,
kde=False # не делать оценку плотности распределения
);
plt.axvline(10, 0, 1, ls='-', c='black');
plt.axvline(5, 0, 1, ls='--', c='black');
plt.axvline(15, 0, 1, ls='--', c='black');
plt.annotate("Среднее", (10, 500), (11, 600), arrowprops={"arrowstyle": '->'});
plt.annotate("Здесь лежат около 95% исходов", (4.5, 100));
# Подсчитаем процент попавших в диапазон от +5 до +15 точек
sum([1 if x >= 5 and x <= 15 else 0 for x in X]) / len(X)
0.9538
Случай дискретных величин выглядит слегка вырожденно.
X = []
for index in range(100):
x = 1 if np.random.uniform() > 0.3 else 0
X.append(x)
sns.distplot(X, kde=False);
Задача теории вероятностей - это уметь описывать случайные величины.
Задача математической статистики - обратная. По выборке из случайных значений, определить что это за величина (её свойства). Любая функция от выборки - например среднее значение, или самое часто встречающееся (в статистике - мода), - называется статистикой.
Анализ данных и машинное обучение - это в некотором смысле продолжение статистики, так как мы по случайной выборке (датасету) должны установить зависимость между признаками и целевой величиной.
Пример¶
Представим, что у нас есть замеры роста 300 человек. Мы не знаем что это за случайная величина, но мы можем рассмотреть её различные описательные статистики, и что-то сказать о её поведении.
height = [
np.random.normal(170, 5) for _ in range(300) # синтетические данные
]
sns.distplot(height, kde=False);
Описательные статистики¶
pd.DataFrame({'height' : height}).describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| height | 300.0 | 169.753857 | 4.719362 | 155.801176 | 166.703804 | 169.715865 | 172.799569 | 182.007264 |
Здесь мы видим:
количество (count) записей,
среднее (mean) для всех замеров роста,
стандартное отклонение (std) - для нормального распределения, 95% данных лежат в интервале (
среднее - 2 * стандартное отклонение,среднее + 2 * стандартное отклонение),25% данных ниже значения, указанного в столбце 25%
аналогично с другими процентными значениями (эти статитистики называются процентилями),
минимум и максимум по всем данным.
Три важных теоремы¶
Закон больших чисел: если все случайные величины у нас независимы и одинаково распределены, то выборочное среднее стремится при увеличении числа испытаний к математическому ожиданию.
Математическое ожидание - это взвешенные по вероятностям исходы, то есть в дискретном случае,
где \(x_i\) - исходы (значения) случайной величины, а \(p_i\) - их вероятность.
По сути, это означает, что в условиях незнания среднего по всем возможным ситуациям (по “всем данным в мире”), мы можем при большом количестве данных заменить его выборочным средним. В нашем при мере с ростом, это означает, что средний рост по всё более увеличивающейся выборке будет ближе к некоторому истинному значению (по “всем данным в мире”).
Центральная предельная теорема: для независимых случайных величин из одного распределения со средним \(M\) и стандартным отклонением \(S\), их выборочное среднее стремится (при увеличении количества испытаний \(n\)) к нормальному распределению с тем же средним и разбросом \(\frac {S} {\sqrt n}\).
Возвращаясь к нашему примеру с ростом, это означает, что по мере роста выборки, средний рост будет распределен как нормальная случайная величина, и чем точнее нам нужно его измерять - тем больше данных нам нужно.
Условная вероятность и теорема Байеса
Тут мы подходим к одному из краеугольных камней машинного обучения. Начнем с двух вопросов:
Насколько вероятно, что через час будет дождь? Пусть это \(A\)
Насколько вероятно, что через час будет дождь, если он уже идёт? Пусть вероятность дождя сейчас \(B\).
Без математики понятно, что речь идёт о разных ситуациях, что в математике формализуют как условную вероятность (определение):
где \(\cap\) обозначает И (пересечение множеств), то есть совместную вероятность обоих случаев сразу.
Практически из определения, вытекает теорема Байеса:
В терминах дождей, это означает, что
вероятность что дождь будет через час, если он идёт сейчас = вероятность дождя сейчас, если он будет через час * вероятность дождя через час / вероятность дождя сейчас.
В данном примере мы ничего напрямую не выигрываем от теоремы (если только мы не метеорологи), но давайте рассмотрим другую, более практическую задачу.
Есть две корзины с печеньем:
В первой 30 ванильных и 10 шоколадных,
Во второй - 20 ванильных и 20 шоколадных.
Мы в темноте вытаскиваем наугад из какой-то корзины ванильное печение. Какова вероятность, что мы вытащили её из первой?
Жизненный опыт подсказывает, что скорее всего из первой, так как в ней больше ванильных. Теорема Байеса же скажет, что вероятность вытащить из первой равна произведению вероятностей выбрать первую корзину \(P(A)\), выбрать из неё ванильную \(P(B | A)\), и всё это поделить на вероятность вытащить ванильную из всех корзин \(P(B)\).
prior = 1 / 2 # вытаскиваем из случайной корзины. это наше A
likelihood = 3 / 4 # вероятность ванильной печеньки в первой корзине. это наше P(B|A)
evidence = (30 + 20) / (20 + 20 + 30 + 10) # вероятность вытащить ванильную печеньку вообще из всех корзин. P(B)
posterior = prior * likelihood / evidence
assert posterior == 3 / 5 # выбросим ошибку, если равенство не выполняется
posterior
0.6
Это конечно замечательно, что мы можем сказать вероятность, конечно, но какая польза от всего этого? А польза в рамках анализа данных и машинного обучения, следующая. Задачу машинного обучения часто ставят как поиск параметров, таких что:
максимум вероятности получить (параметры | датасета), и поскольку такую вероятность мы саму по себе не знаём, то “проворачивают ручку Байеса”:
вероятность (параметров | данные) = вероятность данных при параметрах * вероятность параметров / вероятность данных.
При максимизации вероятности слева, знаменатель справа не меняется (он не зависит от параметров модели), поэтому его даже не всегда считают. Если говорить простыми словами - при машинном обучении часто ищутся те параметры модели, которые имеют максимальную вероятность для имеющегося датасета.
Заключение¶
Мы не будем напрямую пользоваться указанными теоремами. Нам важно следующее следствие:
Чем больше в выборке наблюдений, тем лучше можно оценивать характеристики процесса генерации “всех данных в мире” (data generation process). Но поскольку у нас есть только выборка, то инструменты математической статистики очень пригождаются в анализе данных и машинном обучении.
1.3 А теперь… почему всё это работает¶
Если вы до этого чего-то не поняли, или вообще ничего не поняли, не расстраивайтесь.
Сейчас будет еще сложнее.
Обрадую - после этого будет всё только практика, и сравнительно легко по сравнению с тем, о чем будет сейчас.
Probability-almost-correct (PAC-) обучаемость¶
Всё это конечно замечательно, запустить алгоритм на данных, который нам выдаст модель, которая уловила в данных какие-то закономерности с некоторой ошибкой… А что если данных много, они большие, и их вообще человеку не понять? Не будем же мы проверять каждый ответ руками, смысл?
Вопрос: можем ли мы верить моделям даже в пределах их ошибки?
Ответ: да, но не всегда.
Что вообще означает, что алгоритм может выдать обучившуюся модель? Пусть у нас есть некоторый алгоритм, который выдал на данных нам модель, которая работает с некоторой ошибкой.
Рассмотрим следующие понятия:
Ошибка генерализации - среднее значение ошибки на всех данных в мире. Мы её не знаем на самом деле.
Ошибка модели на тренировочном/тестовом множестве - среднее значение ошибки на выбранном известном множестве.
Желательно бы построить такую модель, которая будучи обученной на известном множестве, имела бы минимальную ошибку генерализации.
Алгоритм называется PAC-обучаемым, если
Выбрав порог ошибки
E, например не более 1% в среднем от любых входных данных,Фиксируя нашу уверенность
P(это некоторая вероятность),Будет иметь место факт: существует количество данных
n, выше которого вероятность ошибки вышеEниже1 - P.
То есть, алгоритм выдаёт такую модель, которая даёт ошибку в
1 - Pслучаев выше чемE, начиная с некоторого числа примеровn.
Существует даже формула на такой размер данных. Но она нам не нужна, все равно мы тут данные не генерируем :)
# один из примеров такой формулы - для задачи классификации
# конкретно эта работает только в случае, если алгоритм выдает конечное число моделей
def estimate_error(models_number, data_size, error_probability):
return np.log(models_number / error_probability) / data_size
"Для миллиарда моделей и трехста примеров, с вероятностью 99%% - оценка ошибки классификатора будет менее: %.4f (доля неправильных ответов)" % estimate_error(10 ** 9, 300, 0.01)
'Для миллиарда моделей и трехста примеров, с вероятностью 99% - оценка ошибки классификатора будет менее: 0.0844 (доля неправильных ответов)'
Миллиард моделей - это не так уж и много. Тем не менее, компьютерные алгоритмы выдают конечное число моделей - так как точность компьютерных чисел не бесконечная (но очень большая). Вывод: формулы сами по себе не очень полезны: количество моделей подсчитать трудно. Да и не нужно.
Мы попробуем на синтетических данных убедиться, что с ростом количества данных алгоритмы работают лучше.
Рассмотрим пример с ростом человека. Есть все люди мира, какие только могут быть, у нас же только ограниченная выборка, по которой мы можем делать выводы. Так вот, представим что мы хотим предсказывать вес человека по росту, тогда для PAC-обучаемого алгоритма с ростом обучающей выборки должно расти качество.
weight = [
sample - 110 - np.random.normal(0, 1) for sample in height
]
sns.pairplot(data=pd.DataFrame({'weight': weight, 'height': height}));
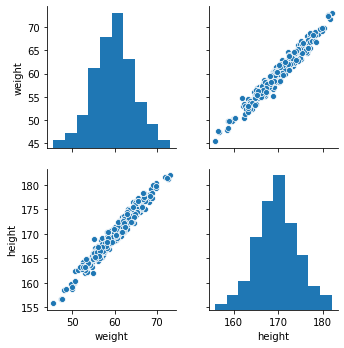
Мы рассмотрим три алгоритма. Линейный (\(y = kx + b\), где k и b такие, чтобы ошибка была наименьшей), алгоритм, строящий решающее дерево (набор правил вида если x > 5, то y = 2) и алгоритм ближайших соседей. Второй мы рассмотрим в двух вариантах - с обрезкой по глубине (по количеству вопросов) и без, и метод ближайших соседей, который запоминает данные и выдает усредненные значения по нескольким соседям.
%%time
# эта магическая команда замеряет время работы ячейки Jupyter
# импортируем алгоритм, строящий линейные модели
from sklearn.linear_model import LinearRegression
# импортируем алгоритм решающего дерева
from sklearn.tree import DecisionTreeRegressor
# импортируем алгоритм ближайших соседей
from sklearn.neighbors import KNeighborsRegressor
# импортируем подсчет средней абсолютной ошибки
from sklearn.metrics import mean_absolute_error
print("""
Учимся на увеличивающемся количестве точек по сотне раз,
качество проверяем на "всех данных в мире" - усредняем.
Ошибкой считаем разницу более одного килограмма.
""")
results = []
estimator_names = [
'linear', 'deep tree', 'shallow tree', 'neighbors'
]
for number_points in range(5, 31):
errors = {
name: [] for name in estimator_names
}
for index in range(100):
random_indices = np.random.randint(
0, len(weight),
size=number_points
)
for iterator, estimator in enumerate([
LinearRegression(),
DecisionTreeRegressor(random_state=1),
DecisionTreeRegressor(max_depth=3, random_state=1),
KNeighborsRegressor(weights='distance')
]):
yhat = estimator.fit(
np.array(height).reshape(-1, 1)[random_indices],
np.array(weight)[random_indices]
).predict(
np.array(height).reshape(-1, 1)
)
errors[estimator_names[iterator]].append(
mean_absolute_error(weight, yhat)
)
percents = {}
for name in estimator_names:
percents[name] = sum([
1 if error > 1. else 0 for error in errors[name]
])
results.append([
number_points,
percents[name],
np.mean(errors[name]),
name
])
print("""Шаг %d процент "плохих" моделей: линейный алгоритм: %.f, глубокое дерево: %.f, неглубокое дерево %.f, соседи %.f""" % (
number_points,
percents['linear'],
percents['deep tree'],
percents['shallow tree'],
percents['neighbors']
))
Учимся на увеличивающемся количестве точек по сотне раз,
качество проверяем на "всех данных в мире" - усредняем.
Ошибкой считаем разницу более одного килограмма.
Шаг 5 процент "плохих" моделей: линейный алгоритм: 35, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 6 процент "плохих" моделей: линейный алгоритм: 32, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 7 процент "плохих" моделей: линейный алгоритм: 32, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 8 процент "плохих" моделей: линейный алгоритм: 27, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 9 процент "плохих" моделей: линейный алгоритм: 18, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 10 процент "плохих" моделей: линейный алгоритм: 12, глубокое дерево: 100, неглубокое дерево 100, соседи 99
Шаг 11 процент "плохих" моделей: линейный алгоритм: 10, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 12 процент "плохих" моделей: линейный алгоритм: 9, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 13 процент "плохих" моделей: линейный алгоритм: 17, глубокое дерево: 100, неглубокое дерево 100, соседи 100
Шаг 14 процент "плохих" моделей: линейный алгоритм: 3, глубокое дерево: 100, неглубокое дерево 100, соседи 99
Шаг 15 процент "плохих" моделей: линейный алгоритм: 6, глубокое дерево: 100, неглубокое дерево 100, соседи 99
Шаг 16 процент "плохих" моделей: линейный алгоритм: 2, глубокое дерево: 100, неглубокое дерево 100, соседи 97
Шаг 17 процент "плохих" моделей: линейный алгоритм: 4, глубокое дерево: 100, неглубокое дерево 100, соседи 97
Шаг 18 процент "плохих" моделей: линейный алгоритм: 0, глубокое дерево: 100, неглубокое дерево 100, соседи 99
Шаг 19 процент "плохих" моделей: линейный алгоритм: 1, глубокое дерево: 100, неглубокое дерево 100, соседи 96
Шаг 20 процент "плохих" моделей: линейный алгоритм: 2, глубокое дерево: 100, неглубокое дерево 100, соседи 95
Шаг 21 процент "плохих" моделей: линейный алгоритм: 2, глубокое дерево: 100, неглубокое дерево 100, соседи 98
Шаг 22 процент "плохих" моделей: линейный алгоритм: 1, глубокое дерево: 99, неглубокое дерево 100, соседи 91
Шаг 23 процент "плохих" моделей: линейный алгоритм: 2, глубокое дерево: 100, неглубокое дерево 100, соседи 91
Шаг 24 процент "плохих" моделей: линейный алгоритм: 1, глубокое дерево: 97, неглубокое дерево 100, соседи 86
Шаг 25 процент "плохих" моделей: линейный алгоритм: 0, глубокое дерево: 99, неглубокое дерево 100, соседи 86
Шаг 26 процент "плохих" моделей: линейный алгоритм: 0, глубокое дерево: 100, неглубокое дерево 100, соседи 86
Шаг 27 процент "плохих" моделей: линейный алгоритм: 3, глубокое дерево: 98, неглубокое дерево 100, соседи 86
Шаг 28 процент "плохих" моделей: линейный алгоритм: 0, глубокое дерево: 99, неглубокое дерево 100, соседи 83
Шаг 29 процент "плохих" моделей: линейный алгоритм: 1, глубокое дерево: 99, неглубокое дерево 100, соседи 83
Шаг 30 процент "плохих" моделей: линейный алгоритм: 0, глубокое дерево: 97, неглубокое дерево 100, соседи 74
Wall time: 9.03 s
sns.scatterplot(x="points", y="error", size="percent", hue="type", data=pd.DataFrame(results, columns=[
'points', 'percent', 'error', 'type'
]));
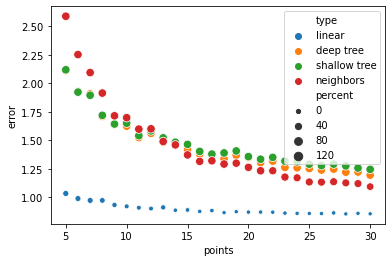
Из этого изображения вовсе не следует, что линейный алгоритм вот лучше всех (но на этих данных, да, лучше). Это иллюстрация связи “всех данных в мире” и уменьшения ошибки с ростом количества данных (как видим с разной скоростью). Почему здесь линейный случай лучше всего работает - да потому что изначально в наши синтетических данных линейная связь с небольшим шумом.
И тут возникает вопрос… когда алгоритм является PAC-обучаемым? - то есть будет ли с ростом данных падать ошибка?
PAC-обучаемость для алгоритмов устанавливается путем проверки его VC-размерности (размерности Вапника-Червоненкинса) на конечность.
VC-размерность — это число - максимальное количество примеров, которые алгоритм сможет разделить всеми возможными способами на две части (в случае классификации). Основной результат теории статистического обучения: если VC-размерность алгоритма конечна, то он является PAC-обучаемым. Интуитивно, можно построить хороший классификатор, если алгоритм может разделять данные на два класса всеми способами.
Деревья без обрезки не являются PAC-обучаемыми, потому что количество способов растёт неограниченно вместе с размером датасета. Классификатор ближайших соседей - является PAC-обучаемым когда точки “кучкуются” - так или иначе кластеризуются на группы классов (вероятность попасть в один класс падает вместе с ростом расстояния между точками).
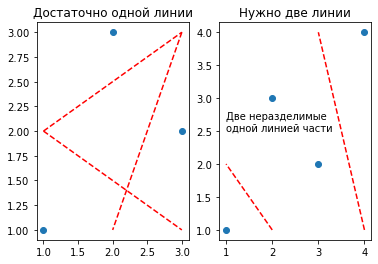
Пример установления VC-размерности для линейного алгоритма (на плоскости): он может разделить датасет из трёх точек на две части. Чтобы разделить датасет из четырех точек на две части (всеми возможными способами), одной линии нашего алгоритма уже недостаточно. Следовательно, размерность такого алгоритма для плоскости равна 3 (конечна).
plt.subplot(1, 2, 1);
plt.title('Достаточно одной линии');
plt.scatter([1, 2, 3], [1, 3, 2]);
plt.plot([1, 3], [2, 1], c='red', ls='--');
plt.plot([1, 3], [2, 3], c='red', ls='--');
plt.plot([3, 2], [3, 1], c='red', ls='--');
plt.subplot(1, 2, 2);
plt.title('Нужно две линии');
plt.scatter([1, 2, 3, 4], [1, 3, 2, 4]);
plt.plot([2, 1], [1, 2], c='red', ls='--');
plt.plot([4, 3], [1, 4], c='red', ls='--');
plt.annotate("Две неразделимые\nодной линией части", (1, 2.5));
Как ни странно, все эти знания нам в ближайшей пятидневной практике не понадобятся. Однако из всей этой теории (статистического обучения) вытекает следующее.
Алгоритмы - работают! Правда, с некоторого количества примеров.
Работают не все алгоритмы. Существует теорема “Нет бесплатных обедов” (
no free lunch-теорема), которая говорит, что универсальный алгоритм всегда потерпит неудачу (найдутся для него примеры). То есть мы должны “подтолкнуть” алгоритм некоторым знанием о задаче к решению. Именно поэтому линейный алгоритм на данных с ростом и весом проявил себя лучше.Ошибку следует рассматривать из трех компонент: неустранимая ошибка (ошибка идеального классификатора, или
Bayes error rate), ошибку аппроксимации (смещение) и ошибку оценивания (разброс). На этом остановимся подробнее в виде примера.
Вспомним, что мы можем выбирать алгоритмы. Пока неважно какие. Они могут давать разные множества моделей (как по количеству, так и по их сложности).
Неустранимая ошибка - это ошибка идеального классификатора на всех данных. Она даже ниже ошибки разметки человеком, и заложена самой природой данных - представьте что у нас есть описание “всех данных в мире” - и тогда если существует хотя бы какая-нибудь вероятность принадлежности примера более чем одному классу - неустранимая ошибка имеет место. Для детерминированных данных (не вероятностных) такая ошибка равна нулю.
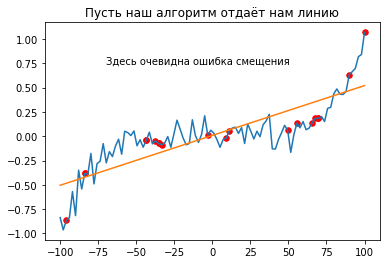
Ошибка смещения - это ошибка выбора класса алгоритма, возникает когда модели не способны приблизить данные достаточно.
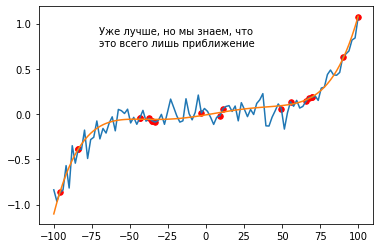
Ошибка разброса - это ошибка, возникающая вследствие того, что созданная алгоритмом модель - является только приближением к некоторой “идеальной” модели, но не является ей. Она появляется, когда предсказания отличаются от среднего не так же, как предсказываемая величина.
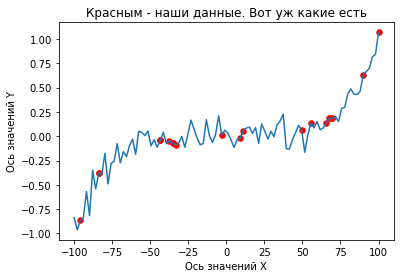
X = np.linspace(-100, 100, 100)
np.random.seed(1)
Y = np.array([
x ** 5 / 100 ** 5 + np.random.normal() / 10 for x in X
])
train_indices = np.random.randint(0, len(X), size=20)
plt.title("Красным - наши данные. Вот уж какие есть");
plt.plot(X, Y);
plt.scatter(X[train_indices], Y[train_indices], s=30, c='red');
plt.xlabel("Ось значений X");
plt.ylabel("Ось значений Y");
yhat = LinearRegression().fit(
np.array(X[train_indices]).reshape(-1, 1), # здесь мы подстраиваем данные под формат
np.array(Y[train_indices]).reshape(-1, 1) # библиотеки scikit-learn, о которой конечно же поговорим
).predict(np.array(X).reshape(len(X), 1))
plt.title('Пусть наш алгоритм отдаёт нам линию');
plt.plot(X, Y);
plt.plot(X, yhat);
plt.scatter(X[train_indices], Y[train_indices], s=30, c='red');
plt.annotate("Здесь очевидна ошибка смещения", (-70, 0.75));
“Подтолкнём” наш алгоритм ближе к задаче, дав возможность использовать различные степени X.
max_power = 5
X_powered = np.array([
[(x ** power) for power in range(1, max_power + 1)] for x in X
])
yhat = LinearRegression().fit(
X_powered[train_indices].reshape(-1, max_power),
Y[train_indices].reshape(-1, 1)
).predict(np.array(X_powered).reshape(len(X_powered), max_power))
plt.plot(X, Y);
plt.plot(X, yhat);
plt.scatter(X[train_indices], Y[train_indices], s=30, c='red');
plt.annotate("Уже лучше, но мы знаем, что\nэто всего лишь приближение", (-70, 0.75));
Обогатим наш алгоритм и дадим возможность использовать (очень) большие степени.
min_power = 10
max_power = 20
X_new = np.array([
[(x ** power) for power in range(min_power, max_power + 1)] for x in X
]).reshape(len(X), -1)
yhat = LinearRegression().fit(
X_new[train_indices], np.array(Y[train_indices]).reshape(-1, 1)
).predict(X_new)
plt.title('Мы выбрали слишком "богатый" на варианты способ!');
plt.plot(X, Y);
plt.plot(X, yhat);
plt.scatter(X[train_indices], Y[train_indices], s=30, c='red');
plt.annotate("Совсем не то", (-70, 0.75));
plt.ylim(-1, 1);
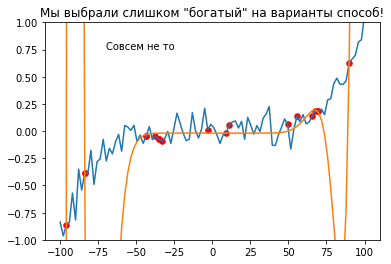
Получается несколько случаев, как модель может подходить под данные:
Недообучение: низкие метрики на тренировочном и тестовом множестве (которые частный случай “всех данных в мире”) - первый случай,
Переобучение: высокие метрики на тренировочном и низкие на тестовом - последний случай,
Генерализация: хорошие метрики на обоих множествах - будем считать второй случай,
Хорошие метрики на тестовом и слабые на тренировочном - редкий случай, иногда встречается когда тестовые данные слишком малы или сильно отличаются от тренировочных.
Заключение¶
Резюмируя этот наш раздел, важно знать вот что.
Алгоритмы, которые мы будем в дальнейшем использовать, разные.
Соответственно, ошибаются они тоже по-разному.
Иногда им они слишком простые, чтобы подойти под данные, иногда перебор сложные. Когда мы будем рассматривать конкретные практические алгоритмы, мы узнаем, что можно с этим делать.
На этом поздравляю! Самое сложное в курсе уже пройдено. Дальше будет только практика, практика, и еще раз практика (которая критерий истины).
1.4 Инструментарий аналитика данных: python и jupyter lab¶
Для анализа данных можно использовать различные языки и инструменты, например языки R, Julia, визуальные инструменты Dataiku или Orange3. В сфере программного обеспечения часто можно найти множество альтернативных решений под каждую задачу.
Мы выбираем python и среду разработки Jupyter Lab не просто потому что они популярные. Популярность - это следствие наличия серьезной экосистемы, то есть набора инструментов и пакетов. python для анализа данных стал особо популярен в результате усилий Google и Facebook, которые выпустили большие полезные библиотеки для работы с данными. Jupyter Lab - это один самых частых инструментов ввиду своей простоты и при этом - удобства работы.
Все вот эти тетрадки были созданы с помощью Jupyter Lab, и его использует в практике очень много аналитиков. Так же как и python: порог вхождения у него не запредельный, а возможности, как у универсального языка с “кучей батареек” - практически неограничены (по-крайней мере для типичных задач).
python crash course¶
# переменные - ссылки на значения
string_variable = "Это строка"
integer_variable = 42 # целое число
float_variable = 3.14 # вещественное число
string_variable, integer_variable, float_variable
('Это строка', 42, 3.14)
# Кортеж - упорядоченный неизменяемый список значений
tuple_example = (1, 23, "Хопа")
tuple_example
(1, 23, 'Хопа')
# Список - изменяемый набор значений
list_example = [1, 2, 3, 4, 5]
# список можно "срезать" по индексам
# индексы всегда начинаются с нуля!
list_example[2], list_example[:2], list_example[-2:], list_example[::2]
(3, [1, 2], [4, 5], [1, 3, 5])
# словарь - множество пар "ключ -> значение"
dict_example = {
'серебряный': 100.100,
'золотой': 200.200
}
dict_example['серебряный'], dict_example.get('платиновый', 'значение по умолчанию')
(100.1, 'значение по умолчанию')
# элементам списков и словарей можно присваивать значения
dict_example['платиновый'] = list_example[2] = 159
list_example, dict_example
([1, 2, 159, 4, 5], {'серебряный': 100.1, 'золотой': 200.2, 'платиновый': 159})
# циклы - по последовательности и по условию
result = ""
for value in ["A", 2, 24 // 2, "B"]:
result += str(value) + " "
print(result)
value = 0
while value < 42:
value += 1 # не забудьте, а то цикл будет бесконечным без выхода
print(value)
A 2 12 B
42
# списки и словари можно инициализировать циклами
range_list = [x * 2 for x in range(1, 11, 2)]
range_dict = {x: x + 2 for x in range(1, 11, 2)}
range_list, range_dict
([2, 6, 10, 14, 18], {1: 3, 3: 5, 5: 7, 7: 9, 9: 11})
# функции... это почти то же, что и в математике - выход для входа
# а точнее - обособленный блок кода с параметрами
def function(x, a, b):
y = x * a + b
return y
function(2, 10, 20)
40
# класс - это описание объекта
# любой объект может иметь свойства и методы
# тут проще на примере
class ExampleClass:
def __init__(self, a, b):
"""
Такой метод называется конструктор
"""
# self - внутрення ссылка на текущий объект
self.a, self.b = a, b
def function(self, x):
return self.a * x + self.b
# создадим объект - экземпляр класса
example_object = ExampleClass(20, 30)
# и вызовем его метод
example_object.function(2)
70
# классы могут наследоваться, и обычно ожидается что объекты
# унаследованного класса "ведут" себя подобно объектам базового,
# но в деталях могут делать что-то другое
class Inherited(ExampleClass):
def function(self, x):
return self.a * x * x + self.b
example_object = Inherited(20, 30)
example_object.function(2)
110
Как ни странно - это практически всё, что нам понадобится. Помимо этого, нам еще понадобится импорт библиотек, а вот в них уже “кладези всяких полезностей”. Выше мы видели, в какие чудеса они умеют, всё делают за нас, надо их только попросить :)
# вариант импорта из недр библиотеки
import sklearn.datasets as datasets
# другой вариант импорта
from sklearn.cluster import KMeans
# ну и продолжим, раз начали :)
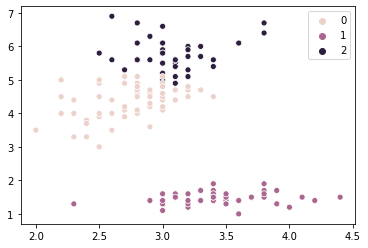
# загрузим датасет из библиотеки
X, y = datasets.load_iris(return_X_y=True)
# KMeans - это класс с методами
clusterer = KMeans(n_clusters=3).fit(X)
# запись X[:, 1] - означает взять ВТОРУЮ колонку массива
sns.scatterplot(x=X[:,1], y=X[:,2], hue=clusterer.labels_);
Заключение¶
python активно развивается. Из основных новшеств - это добавление спецификаций типов в объявления переменных (везде, где они объявляются). Мы пока это не используем, чтобы не усложнять код. Но выглядит это вот так (хотите - пользуйтесь, но потом не жалуйтесь:)). Учтите, эти подсказки по типам, в python 3.6 на самом деле ни на что не влияют.
def example(a: float = None, b: float = 0) -> float:
if a is not None:
return a + b
return None
example(), example(0), example(0, 1)
(None, 0, 1)
example("Hello, ", "world")
'Hello, world'
1.5 Цикл моделирования и кросс-валидация¶
Теперь переходим к самой что ни на есть практике анализа данных. Цикл моделирования - это процесс из нескольких шагов, позволяющих из данных получить применяемую в практике модель. CRISP-DM - это сокращение слов CRoss-Indrustry Standard Process for Data Mining - кросс-индустриальный процесс анализа данных.
Процесс состоит из следующих шагов:
Понимание бизнес-цели. Зачем нам вообще анализ данных в текущей бизнес- или исследовательской задачи. На этом этапе должно быть ясно, зачем нужна модель, и какие у неё должны быть метрики качества.
Разведочный анализ. Это ознакомление с данными, визуальный поиск зависимостей, формулировка гипотез о взаимосвязи.
Подготовка данных. Это важный этап, на котором данные чистятся от битых значений и выбросов (они могут испортить модель), подготавливаются к удобному для моделирования виду.
Моделирование. Построение моделей. Это всего-лишь приблизительно 20% времени от всего процесса, но как раз на этом этапе запускаются алгоритмы, которые выдают модели.
Оценка. Оценка качества модели или ряда моделей. Оценка - это не только метрики, которые минимизировала модель, но еще и бизнес-метрики. Например, средняя ошибка в килограммах это одно, а в рублях - совсем другое. Только на этом этапе можно понять, пригодна ли модель к применению (эксплуатации).
Внедрение. Это развертывание модели для применения. Например, чтобы или сайт, или пользователи, или организации - как-то смогли пользоваться предсказанием модели.
Мониторинг. Это слежение за качеством уже применяемой модели. Обычно, по косвенным и производным признакам качества (растёт прибыль - хорошо!).
В нашем курсе мы модели внедрять не будем (хотя и поговорим как можно). Важно заметить следующее:
В этом процессе можно возвращаться с любого шага на любой шаг назад, но проскакивать вперед шаги нельзя! Иначе просто бессмысленно потратите время.
Пример¶
1.5.1 Понимание задачи и целей¶
Давайте представим, что у нас есть цветочный магазин, который специализируется на цветках ириса, и предлагает их в трёх сортах: Virginica, Versicolor и Setosa. Мы хотели бы автоматически определять что за сорт, без участия каких-либо ботаников. К счастью, ботаники уже создали датасет из 150 цветков, в котором разметили их сорта.
Наша цель - создать модель, которая по признакам цветка определяла бы их сорт. Отбор моделей необходимо производить с учетом того, что сорта стоят по-разному!
1.5.2 Разведочный анализ¶
Ознакомление с данными. Первые попытки понять то, с чем мы имеем дело.
from sklearn.datasets import load_iris
# распечатаем какие есть признаки у данных
iris = load_iris()
iris.feature_names
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
Где-то в интернетах нашлась хорошая картинка

# загрузим данные в pandas-таблицу
features_data = {
iris.feature_names[index]: iris.data[:, index] \
for index in range(len(iris.feature_names))
}
features_data['sort'] = iris.target
features_data['name'] = [
iris.target_names[sort] for sort in iris.target
]
frame = pd.DataFrame(
features_data,
columns=iris.feature_names + ['sort', 'name']
)
# и посмотрим на случайную выборку из 10 цветов
frame.sample(10)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | sort | name | |
|---|---|---|---|---|---|---|
| 7 | 5.0 | 3.4 | 1.5 | 0.2 | 0 | setosa |
| 5 | 5.4 | 3.9 | 1.7 | 0.4 | 0 | setosa |
| 60 | 5.0 | 2.0 | 3.5 | 1.0 | 1 | versicolor |
| 45 | 4.8 | 3.0 | 1.4 | 0.3 | 0 | setosa |
| 55 | 5.7 | 2.8 | 4.5 | 1.3 | 1 | versicolor |
| 65 | 6.7 | 3.1 | 4.4 | 1.4 | 1 | versicolor |
| 103 | 6.3 | 2.9 | 5.6 | 1.8 | 2 | virginica |
| 124 | 6.7 | 3.3 | 5.7 | 2.1 | 2 | virginica |
| 127 | 6.1 | 3.0 | 4.9 | 1.8 | 2 | virginica |
| 91 | 6.1 | 3.0 | 4.6 | 1.4 | 1 | versicolor |
frame.describe(include='all')
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | sort | name | |
|---|---|---|---|---|---|---|
| count | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150.000000 | 150 |
| unique | NaN | NaN | NaN | NaN | NaN | 3 |
| top | NaN | NaN | NaN | NaN | NaN | virginica |
| freq | NaN | NaN | NaN | NaN | NaN | 50 |
| mean | 5.843333 | 3.057333 | 3.758000 | 1.199333 | 1.000000 | NaN |
| std | 0.828066 | 0.435866 | 1.765298 | 0.762238 | 0.819232 | NaN |
| min | 4.300000 | 2.000000 | 1.000000 | 0.100000 | 0.000000 | NaN |
| 25% | 5.100000 | 2.800000 | 1.600000 | 0.300000 | 0.000000 | NaN |
| 50% | 5.800000 | 3.000000 | 4.350000 | 1.300000 | 1.000000 | NaN |
| 75% | 6.400000 | 3.300000 | 5.100000 | 1.800000 | 2.000000 | NaN |
| max | 7.900000 | 4.400000 | 6.900000 | 2.500000 | 2.000000 | NaN |
frame['name'].value_counts()
virginica 50
versicolor 50
setosa 50
Name: name, dtype: int64
Посмотрим на данные визуально, причем попарно
features = iris.feature_names
sns.pairplot(data=frame[features + ['name']], hue="name");
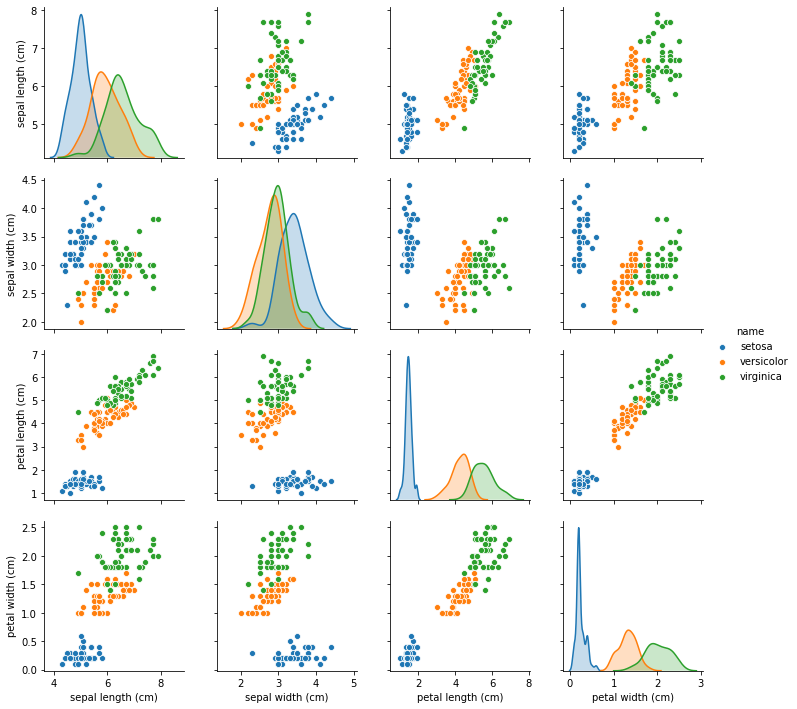
Хорошо видно, что по некоторым признакам сорта образуют хорошие группы! А по некоторым - не очень.
1.5.3 Подготовка данных¶
Вычищать из примеров мы ничего не будем. А вот признак sepal width (cm) - мы уберем, так как по этому признаку цветы очень схожи. Это на самом деле интуиция, которую мы проверим метриками качества в дальнейшем.
reduced_features = list(features) # скопируем
reduced_features.remove('sepal width (cm)')
Разобъем наш датасет на тренировочную и тестовую части. Пусть тестовая часть будет 25% от всего датасета.
from sklearn.model_selection import train_test_split
train, test = train_test_split(
frame,
random_state=1,
test_size=0.25,
stratify=frame.sort # об этом чуть ниже
)
"Столько у нас тренировочных цветов", len(train)
('Столько у нас тренировочных цветов', 112)
1.5.4 Моделирование¶
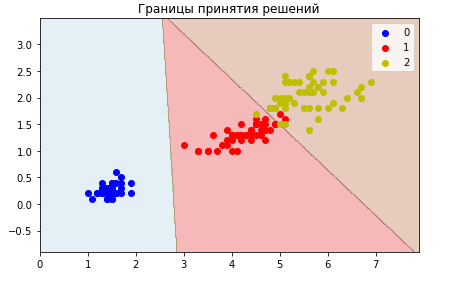
Возьмем простую модель классификации на основе ближайших соседей. Алгоритм предсказывает класс исходя из классов своих ближайших соседей для нового примера. Ближайшие соседи голосуют своим количеством за класс (какого класса рядом больше, тот и выиграл).
Этот алгоритм - на самом деле запоминает всю тренировочную выборку. Вспомним, что он является PAC-обучаемым, если данные по разным классам “кучкуются”, образуют некоторые кластеры. Судя по результатам визуального анализа - наш случай.
from sklearn.neighbors import KNeighborsClassifier
# создадим объект-классификатор и будем определять класс по 5 ближайшим соседям
classifier_5 = KNeighborsClassifier(n_neighbors=5)
# создадим второй, и будем определять уже по 10
classifier_10 = KNeighborsClassifier(n_neighbors=10)
# применим алгоритм к тренировочным данным
classifier_5.fit(train[reduced_features], train.sort)
classifier_10.fit(train[reduced_features], train.sort)
# получим предсказания на тренировочном и тестовом множествах
yhat_train_5 = classifier_5.predict(train[reduced_features])
yhat_test_5 = classifier_5.predict(test[reduced_features])
yhat_train_10 = classifier_10.predict(train[reduced_features])
yhat_test_10 = classifier_10.predict(test[reduced_features])
1.5.5 Проверка качества¶
Выберем в качестве метрики - процент правильно отмеченных цветов. Чем это число выше - тем классификатор лучше. Потом учтем так же, что разные цветы стоят по-разному!
from sklearn.metrics import accuracy_score
print('classifier_5', 'train', "%.2f" % accuracy_score(train.sort, yhat_train_5))
print('classifier_5', 'test', "%.2f" % accuracy_score(test.sort, yhat_test_5))
print('classifier_10', 'train', "%.2f" % accuracy_score(train.sort, yhat_train_10))
print('classifier_10', 'test', "%.2f" % accuracy_score(test.sort, yhat_test_10))
classifier_5 train 0.97
classifier_5 test 0.97
classifier_10 train 0.96
classifier_10 test 0.97
# измерим теперь ошибку в деньгах
# следующая функция подсчитывает таблицу ошибок по классам
prices = {
'setosa': 100,
'versicolor': 120,
'virginica': 200
}
def money_error(true_set, predictions):
cost_true = sum([
prices[true_set['name'][index]] \
for index in true_set.index
])
cost_predicted = sum([
prices[iris.target_names[int(prediction)]] \
for prediction in predictions
])
print("Должно стоить %d, а предсказано %d" % (
cost_true, cost_predicted
))
money_error(test, yhat_test_5)
money_error(test, yhat_test_10)
Должно стоить 5360, а предсказано 5280
Должно стоить 5360, а предсказано 5280
# а посмотрим-ка, как алгоритмы ошибаются
from sklearn.metrics import confusion_matrix
print('5 neighbors')
print(confusion_matrix(test.sort, yhat_test_5))
print()
print('10 neighbors')
print(confusion_matrix(test.sort, yhat_test_10))
5 neighbors
[[12 0 0]
[ 0 13 0]
[ 0 1 12]]
10 neighbors
[[12 0 0]
[ 0 13 0]
[ 0 1 12]]
На главной диагонали это матрицы стоит число правильно классифицированных примеров, а в остальных ячейках - перепутанные при предсказании метки (по горизонтали - актуальные значения, а по вертикали - предсказанные). То есть в ячейке (3 по вертикали, 2 по горизонтали) стоит число примеров, отнесенных моделью к классу 3 вместо 2. А теперь, как и было обещано, проверим со качество всеми признаками (на 10 соседях).
classifier = KNeighborsClassifier(n_neighbors=10)
classifier.fit(train[features], train.sort)
yhat_test = classifier.predict(test[features])
print(confusion_matrix(test.sort, yhat_test))
money_error(test, yhat_test)
[[12 0 0]
[ 0 13 0]
[ 0 2 11]]
Должно стоить 5360, а предсказано 5200
Ну что ж, так и есть, тот признак слегка портил модель. На основании исследования метрик, можно принимать решение, какую модель внедрять.
На этом курсе каждая команда должна пройти эти пять шагов как минимум. Мы приложим все усилия, чтобы у вас это получилось.
Рассмотрим что такое кросс-валидация.
Кросс-валидация - это метод подсчета метрик модели, используя все доступные данные. Делается это для того, чтобы снизить влияние разбиения данных на принятие конечного решения.
Кросс-валидация делается так:
Всё множество разбивается на
Kчастей,На всех частях кроме одной обучается модель,
Качество проверяется на одной отложенной части,
Процесс повторяется
Kраз, пока все части не побудут тестовыми.
Здесь важно пояснить. Если с кросс-валидацией для регрессии всё просто - бьем на части, учимся на одних, проверяем качество на отложенной, то с классификацией всё почти так же… за исключением того момента, что разбиение на части производится стратифицированно: датасет бьется на части так, чтобы соотношение классов в каждой части сохранялось по отношению ко всему датасету. То есть если у нас 1/1/1 для всех цветков ириса, то при разбиении на части этот баланс будет сохранен.
ВНИМАНИЕ! Метод
train_test_splitиз scikit-learn умеет делать стратифицированное разбиение при классификации (с помощью параметраstratify = y). Это нужно. В курсе иногда “наивно” используетсяshuffle(простое перемешивание), что не до конца корректно при классификации. Обращайте на это внимание. Как перемешаны данные - важно.
“В природе” так же встречаются и сильно несбалансированные датасеты - для работы с этим используются отдельные техники: либо классы балансируют, либо работают с регуляризацией (штрафами модели на коэффициенты), либо используют веса для примеров (вес редкого примера выше, такие веса можно передавать третьим параметром fit у некоторых алгоритмов).
from sklearn.model_selection import cross_val_score
metrics = cross_val_score(
KNeighborsClassifier(n_neighbors=3),
X=frame[reduced_features],
y=frame.sort,
cv=5 # пять частей
)
metrics
array([0.96666667, 0.96666667, 0.96666667, 0.96666667, 1. ])
print("Ожидаемое среднее качество %.2f" % metrics.mean())
print("Разброс среднего качества %.2f" % metrics.std())
Ожидаемое среднее качество 0.97
Разброс среднего качества 0.01
Заключение¶
В заключение следует отметить пару вещей:
Процесс CRISP-DM не гарантирует качественной модели, но без него вы точно её не получите,
Модели имеет смысл кросс-валидировать, чтобы использовать все доступные данные. Часто это используют при отборе гиперпараметров - в нашем случае это число ближайших соседей. Но об этом будет еще в нашем курсе позже.
1.6 Обзор всего курса на примерах предсказаний¶
Этот обзорный блок о том, с чем курс нас познакомит.
Второй день - обучение с учителем¶
В основном, на моделях из библиотеки scikit-learn. Начнем все же со специализированных библиотек работы с массивами, табличными данными и их визуализацией, и уделим внимание Exploratory Data Analysis (EDA, разведочный анализ данных). Он в первую очередь нужен для того, чтобы понять что делать с имеющимися признаками и с какого алгоритма имеет смысл начинать.
Далее на примере задач регрессии и классификации, мы рассмотрим такие алгоритмы, как:
линейный. В случае классификации он “пытается” линейно разделить классы.
деревья решений и ансамбли деревьев решений, которые делают разделение на основе “правил”.
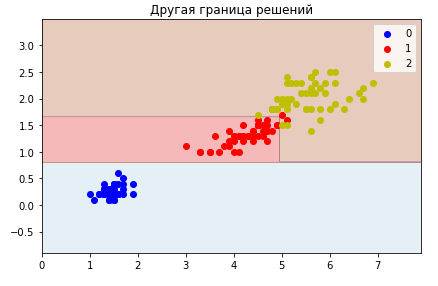
ближайших соседей, когда решение принимается исходя из схожих примеров.
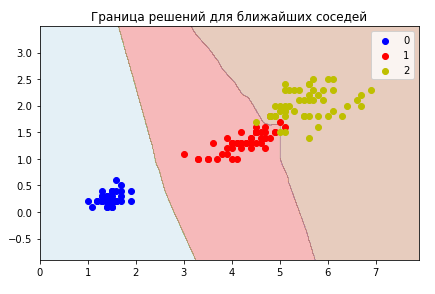
Также на примере ближайших соседей мы посмотрим на базовые способы обработки текстов. С помощью размеченных категорий датасета переписок - мы научимся относить их к определенным классам.
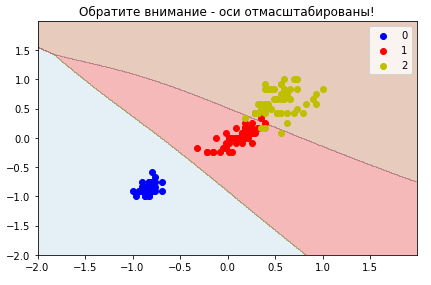
неглубоких нейросетей, которые сами ищут такое признаковое представление, чтобы классы были разделимы.
Третий день - задачи без учителя и временные ряды¶
День будет посвящен работе с неразмеченными данными, без меток правильных ответов - да, с такими данными тоже можно что-то проделывать полезное. Но все же начнется со способов автоматического отбора моделей, а затем будут рассмотрены задачи:
понижения размерности и мы узнаем как можно извлекать из неразмеченных текстов наиболее характеризующие их слова.
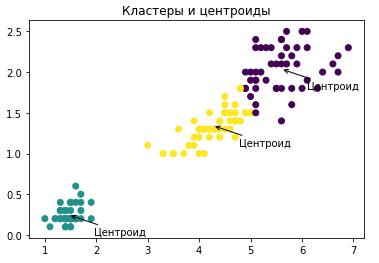
кластеризации, то есть сумеем отнести примеры к той или иной группе, посмотрим один из способов как найти наилучшее число групп,
поиска аномалий в данных, то есть поиска с помощью модели сильно отличающихся от остальных примеров.
Еще мы узнаем как можно продолжать одномерные временные ряды:
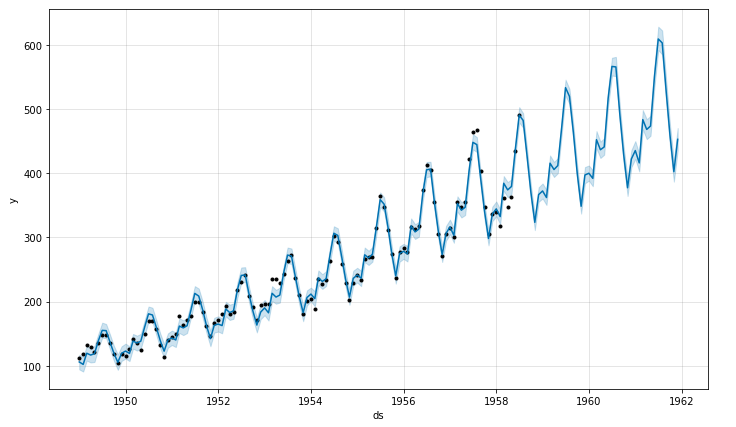
и как можно использовать предсказаний одних моделей как вход для других моделей (на примере погоды).
Четвертый день - нейросети¶
Этот день будет полностью нейросетям и некоторым задачам, которые можно решать с помощью них библиотекой keras. Классические регрессию и классификацию можно решать не только на табличных данных, но и на изображениях, текстах и многомерных временных рядах, например мы рассмотрим:
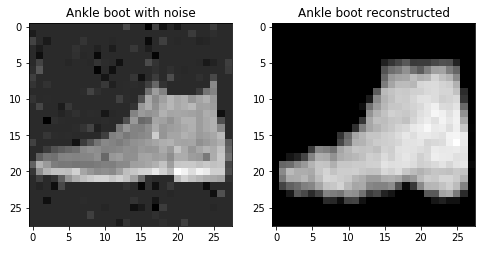
задачу сжатия представления входных данных до вектора и обратного преобразования с помощью сетей-автокодировщиков.
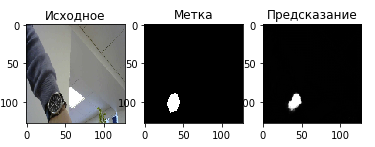
задачу сегментации объектов (например наручных часов на изображении) с помощью сети
Unet.
готовые сети работы с изображениями и текстами. Например, построим простого вопросно-ответного-бота. Ему будут известны и вопросы, и ответы, но вопросы могут быть произвольными. Узнаем как возможно извлекать именованные сущности из текста (имена, события и др.), или суммаризировать тексты (извлекать основное из них).
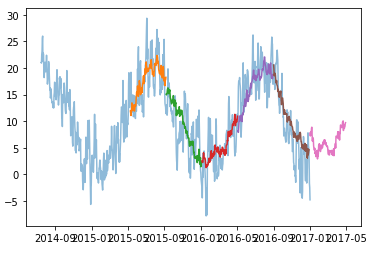
посмотрим, как отдавать сети последовательные многомерные данные (не один ряд, а несколько) - на примере всё той же погоды.
Пятый день - интерпретация, презентация и внедрение моделей¶
А пятый день посвящен тому, что модель - это еще не окончание всех дел, а только начало. В частности узнаем, что:
предсказания моделей можно и нужно интепретировать.
модели можно и нужно разворачивать как сервис, и делать для них интерактивные презентации.
так как модели работают с ошибкой, необходимо убеждаться что они действительно улучшают процесс. Делается это через особый дизайн экспериментов.